
ปัญญาประดิษฐ์แบบรู้สร้าง (Generative AI หรือ GenAI) คือ ปัญญาประดิษฐ์ Deep Learning ประเภทหนึ่งที่สามารถใช้แบบจำลองคณิตศาสตร์สถิติในรูปแบบของอัลกอริทึม (algorithm) เพื่อการเรียนรู้ชุดข้อมูลสำหรับ “สร้าง” ผลลัพธ์ข้อมูลใหม่ เช่น ภาพ เสียง ข้อความ หรือ ข้อมูลในรูปแบบใด ๆ ในขณะนี้ ปัญญาประดิษฐ์แบบรู้สร้าง หรือ GenAI มีระเบียบวิธีการทางสถาปัตยกรรม คือ แบบจำลอง Generative Adversarial Networks (GANs) (Goodfellow I., 2014) ที่ได้รับการพัฒนาและประยุกต์ใช้งานอย่างแพร่หลายในฐานะที่เป็นวิธีสำคัญของ GenAI platforms เช่น ChatGPT, Bard, หรือ DALL-E เป็นต้น
สถาปัตยกรรม deep learning สำหรับ GANs (Goodfellow I., 2014) ประกอบด้วย โครงข่ายประสาทเทียม (Artificial neural networks: ANN) จำนวน 2 โครงข่าย คือ
กระบวนการเรียนรู้ของปัญญาประดิษฐ์ (training process) ของ GANs มีลักษณะที่โครงข่าย Generator และ โครงข่าย Discriminator จะได้รับการฝึกฝน (trained) ในรูปแบบของเกมการแข่งขันแบบซ้ำ (repeated competitive game) กล่าวคือ โครงข่าย Generator มีเป้าหมายที่จะสร้างข้อมูลที่น่าเชื่อถือจนกระทั่งโครงข่าย Discriminator ไม่สามารถจะแยกแยะระหว่างข้อมูลที่เป็นจริงและข้อมูลที่ถูกสร้างขึ้น ในขณะเดียวกัน โครงข่าย Discriminator มีเป้าหมายที่จะปรับปรุงความสามารถของโครงข่ายในการแยกแยะระหว่างข้อมูลที่เป็นจริงและข้อมูลปลอม จึงเป็นกระบวนการที่มีความตรงข้ามกันหรือเป็นปรปักษ์ (adversarial)
กระบวนการเรียนรู้ (training) จะดำเนินต่อไปจนกระทั่งโครงข่าย Generator สามารถสร้างชุดข้อมูลเสมือนจริงขึ้นมาตามการแจกแจงความน่าจะเป็นของข้อมูลจริง ทั้งนี้ แบบจำลองรู้สร้างประเภทต่าง ๆ ก่อนหน้า จะไม่สามารถฝึกฝน และประยุกต์ใช้งานได้ หากไม่มีลักษณะการกระจายหรือความหนาแน่นของความน่าจะเป็น (density of probability) แต่ถ้าเป็นแบบจำลอง GANs ซึ่งเป็น probabilistic generative model ประเภทหนึ่ง จะยังคงสามารถประยุกต์ใช้ทำงานได้แม้ไม่มีข้อมูลเกี่ยวกับความน่าจะเป็นของข้อมูล (Pan Z. et al., 2019) อันสืบเนื่องจาก GANs มีกลไกการเรียนรู้แบบปฏิปักษ์ (adversarial training mechanism) ที่ชาญฉลาด
แบบจำลอง GANs สามารถอธิบายด้วยทฤษฎีเกม คือ โครงข่าย Generator และ โครงข่าย Discriminator จะแข่งขันกันในลักษณะเป็น zero-sum game จนกระทั่งบรรลุถึงจุดดุลยภาพแบบ Nash หรือ Nash equilibrium ภายในกระบวนการฝึกฝน (training) (Creswell A. et al., 2018; Alqahtani H. et al., 2021; and Gui J. et al., 2021) ผลลัพธ์สุดท้ายที่ได้จากระบบการเรียนรู้ของ GANs สามารถอธิบายด้วยทฤษฎีเกมแบบ min-max (Moghaddam et al., 2023) ซึ่งมีรากฐานทางทฤษฎีมาจากงานวิจัยโดยนักคณิตศาสตร์คนดัง John von Neumann (Neumann, 1928) คือ บทพิสูจน์การดำรงอยู่ของ Nash equilibrium ที่สอดคล้องกับกลยุทธ์ min-max หรือ max-min สำหรับ zero-sum game ที่มีผู้เล่นสองราย และมีจำนวนครั้งของการเล่นที่จำกัด (finite game)
ดังที่กล่าวไว้แล้วว่า GANs อาศัยหลักการที่มีระบบ artificial intelligent (AI) สองระบบได้รับการฝึกฝน (train) ให้เรียนรู้ที่จะทำการแข่งขันกัน โดย GANS มีโครงข่าย AI ระบบแรกเป็น neural network เรียกว่า Generator (G) ทำหน้าที่หลอกลวงหรือหลบหลีกระบบที่สอง โดยสร้างข้อมูลปลอมขึ้นมาที่เราเรียกว่า fake sample มีปัจจัยนำเข้า (input) คือ random noise vector Z ซึ่งมักสมมติการกระจายแบบ uniform หรือ normal โดย noise Z จะถูก map ไปยัง data space ใหม่ ด้วยการกระตุ้นจากสิ่งแปลกปลอมที่เพิ่มเข้าในระบบการเรียนรู้เพียงเล็กน้อย บวกเข้ากับสิ่งที่เป็นผลลัพธ์จากความผิดพลาดในเรียนรู้ เพื่อหลบหลีกการจับผิดของ Discriminator D ในช่วงเวลาก่อนหน้า ทำให้ได้เกิดการเรียนรู้ในการปรับตัว (adaptive) สำหรับรอบถัดไป จนกระทั่งสามารถฝึกฝน Generator G ให้สร้าง fake sample G(Z) ที่เป็น multi-dimensional vector มีลักษณะเหมือนข้อมูลจริงมากที่สุด ในทางตรงกันข้าม โครงข่าย AI ระบบที่สองเป็น neural network เรียกว่า Discriminator D ทำหน้าที่เป็น binary classifier โดยใช้ทั้งข้อมูลจริง X และ fake sample ที่สร้างจาก Generator G เพื่อเป็น input สำหรับ Discriminator D ในการสร้าง output คือ การกำหนดความน่าจะเป็นว่า ข้อมูลนั้นเป็นจริงหรือปลอม
ตามภาพที่ 1 กระบวนการจำแนก (classification) โดยโครงข่าย Discriminator D จะทำการจำแนกข้อมูลว่า เป็นข้อมูลจริง X หรือข้อมูลปลอม G(Z) ในขณะที่โครงข่าย Generator G จะสร้างข้อมูลที่มีประสิทธิภาพดีกว่าเดิม จนกระทั่งโครงข่าย Discriminator D ไม่สามารถแยกออกระหว่างเป็นข้อมูลจริง X และข้อมูลปลอม G(Z)
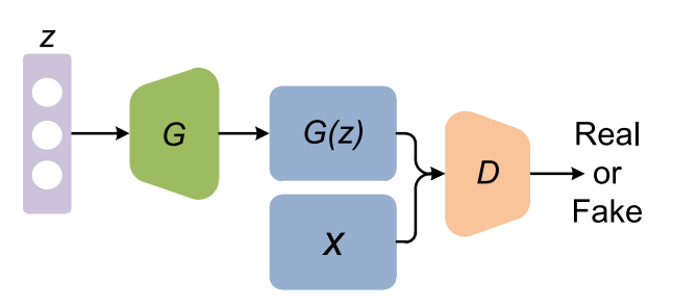
ภาพที่ 1. โครงสร้างสถาปัตยกรรมของ Generative Adversarial Networks แสดงให้เห็นการสร้างข้อมูลปลอม G(Z) ขึ้นมา
จาก latent variable Z โดยโครงข่าย Generator G และการคัดแยกข้อมูลระหว่างข้อมูลจริงและข้อมูลปลอมโดยโครงข่าย Discriminator D
ที่มา: Pan et al. (2019)
ดังนั้น GANs จึงมีประโยชน์จากการไม่ต้องกำหนด probability distribution function, สามารถขยายไปใช้กับ high-dimensional data เช่น ข้อมูลที่มีตัวแปรอธิบายจำนวนมากโดยเปรียบเทียบกับจำนวนกลุ่มตัวอย่าง อันได้แก่ ข้อมูลสำรวจครัวเรือนและแรงงาน ข้อมูล scanner data ของแต่ละรายการอุปโภคบริโภคผ่านเครื่องสแกนก่อนชำระเงิน ข้อมูลตัวแปรที่สร้างจาก text หรือ ข้อมูลตัวแปรที่สร้างจาก interacting ระหว่างตัวแปร เป็นต้น ทั้งนี้ GANs เป็นกระบวนการเรียนรู้แบบ Adaptive Learning คือ deep-learning neural networks สามารถเข้าใจ data distribution ผ่านการ training ทำให้สามารถ “รู้สร้าง” ได้อย่างสมจริงมากขึ้น
ดังโครงสร้างสถาปัตยกรรมตามภาพที่ 2 กระบวนการที่สำคัญประการหนึ่ง คือ Backpropagation ซึ่งเป็นกระบวนการฝึกโครงข่ายประสาทเทียม (neural network training process) ด้วยการป้อนอัตราผิดพลาด (error rates) กลับเข้าไปในโครงข่ายเพื่อให้มีความแม่นยำมากขึ้น โดยจะเปรียบเทียบผลลัพธ์ของโครงข่ายกับผลลัพธ์ที่ต้องการ เพื่อคำนวณข้อผิดพลาด และปรับน้ำหนักของการเชื่อมต่อระหว่าง neurons เพื่อลดข้อผิดพลาดในครั้งต่อไป กระบวนการ Backpropagation มีขั้นตอน คือ (1) ป้อนข้อมูลเข้าสู่โครงข่ายและคำนวณผลลัพธ์, (2) เปรียบเทียบผลลัพธ์ของโครงข่ายกับผลลัพธ์ที่ต้องการและคำนวณข้อผิดพลาด, และ (3) ปรับน้ำหนัก (reweights) ของการเชื่อมต่อระหว่าง neurons เพื่อลดข้อผิดพลาด ตัวอย่างเช่น ความแตกต่างระหว่างค่าจริง
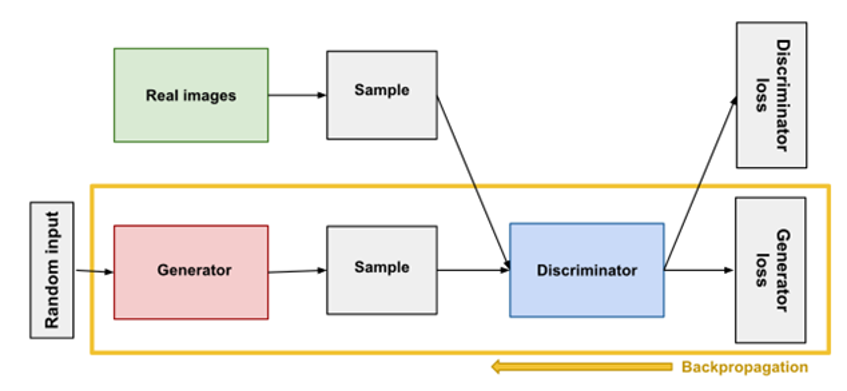
ภาพที่ 2a. กระบวนการ Backpropagation ในการฝึกฝนโครงข่าย Generator
ที่มา: https://developers.google.com/machine-learning/gan/generator

ภาพที่ 2b. กระบวนการ Backpropagation ในการฝึกฝนโครงข่าย Discriminator
ที่มา: https://developers.google.com/machine-learning/gan/discriminator
อีกกระบวนการสำคัญที่ควรกล่าวถึง คือ hyperparameter tuning อันเป็นส่วนสำคัญสำหรับการแก้ปัญหา optimization โดย hyperparameters คือ พารามิเตอร์ที่กำหนดค่าก่อนเริ่มกระบวนการฝึกแบบจำลอง ซึ่งสำหรับแบบจำลองการเรียนรู้เชิงลึก (deep learning models) สามารถมี hyperparameters ได้ตั้งแต่ไม่กี่ตัวจนถึงหลายร้อยตัว ค่าที่กำหนดสำหรับ hyperparameters จะส่งผลต่ออัตราการเรียนรู้ (learning rate) ของแบบจำลอง และตัวควบคุมอื่น ๆ ในระหว่างกระบวนการ training เช่น Batch size, จำนวนชั้นโครงข่าย (layers), จำนวนครั้ง (epochs), หรือ การเพิ่มคุณสมบัติพิเศษบางประการโดยผ่าน hyperparameters ของ Loss function ในการเรียนรู้ข้อมูลที่ผิดปกติ (anomaly detection) ในตลาดหุ้น เป็นต้น แน่นอนว่า ค่า hyperparameters ที่กำหนด จะส่งผลต่อประสิทธิภาพของแบบจำลองขั้นสุดท้าย (final model) ด้วย
โดยสรุปสำหรับการพยากรณ์ด้วยวิธีทางปัญญาประดิษฐ์ด้วย GANs คือ กระบวนการ training โครงข่าย GANs ทั้งสอง สามารถช่วยให้เราเรียนรู้เกี่ยวกับลักษณะและรูปแบบการกระจายของข้อมูลจริง ซึ่งโครงข่าย Generator จะพยายามสร้างข้อมูลที่มาจาก density cloud ของข้อมูลจริง ในขณะที่โครงข่าย Discriminator พยายามจำแนกข้อแตกต่างเปรียบเทียบกับข้อมูลจริง ช่วยให้กระบวนการคำนวณมีความแม่นยำมากขึ้น
จากการนำความสามารถในการรู้สร้าง (generative) ของแบบจำลอง GANs มาใช้อย่างแพร่หลายทางด้านมืด เช่น การทำ Deepfake (Deep Learning + Fake) โดยนำใบหน้าคนดัง หรือบุคคลสำคัญมาใช้ในสื่อลามกโดยไม่ได้รับความยินยอม, การนำมาใช้เป็นเครื่องมือสร้างความปั่นป่วนในประเทศอเมริกา โดยมีการปลอมแปลงทั้งโดนัลด์ ทรัมป์ และ บารัค โอบามา เพื่อหวังผลจากปฏิบัติการข่าวสารข้อมูลทางการเมือง, หรือ ในปัจจุบัน ประเทศไทยมีการใช้เทคโนโลยี Deepfake โดยแก๊ง call center ใช้วิธีวิดีโอคอลมาหาเหยื่อ อ้างตัวเป็นตำรวจ หลอกให้เหยื่อโอนเงิน โดยตัดต่อเสียงให้เข้ากับใบหน้าของตำรวจ เพื่อหลอกให้เหยื่อเชื่อว่าเป็นตำรวจจริง
ในขณะเดียวกัน ผลกระทบในทางบวกของแบบจำลอง GANs ต่อมนุษยชาติในขณะนี้ คือ แบบจำลอง GANs กำลังมีอิทธิพลสำคัญต่อการเปลี่ยนแปลงทางเศรษฐกิจและธุรกิจ เพราะอยู่เบื้องหลังความฉลาดอย่างก้าวกระโดดของปัญญาประดิษฐ์ ทำให้มนุษย์สามารถเข้าถึง ใช้งาน และ ร่วมฝึกฝนปัญญาประดิษฐ์ผ่าน GenAI platforms เช่น ChatGPT, DALL-E และ Google’s Bard เป็นต้น จนทำให้ประชาคมโลกต่างเห็นโอกาสในการเสริมกัน (complementary) ของแรงงานที่มีทักษะด้านการคิดวิเคราะห์ (cognitive analytical skills) หรือ สามารถใช้ปัญญาประดิษฐ์ในการทำงานสร้างสรรค์ ในขณะที่เราเห็นความเสี่ยงในมิติความเหลื่อมล้ำทางเศรษฐกิจสังคมจากการทดแทน (substitutive) สำหรับแรงงานที่ด้อยโอกาสในการเข้าถึงการศึกษาคุณภาพ เป็นแรงงานไร้ทักษะหรือทำงานที่ไม่ต้องใช้ทักษะการวิเคราะห์และความคิดสร้างสรรค์
การนำแบบจำลอง GANs มาประยุกต์ใช้ในงานวิจัยทางเศรษฐศาสตร์ ยังมีค่อนข้างน้อย ตามผลการค้นหาโดย Google Scholar ปัจจุบัน คือ เดือนมกราคม 2567 เกือบทั้งหมดจะเกี่ยวข้องการกับพยากรณ์ข้อมูลอนุกรมเวลา โดยเฉพาะข้อมูลในตลาดหุ้น และ การตรวจสอบโอกาสเกิดวิกฤตหุ้นตกฉับพลันรุนแรง (market crash)
แม้จะมีงานวิจัยเฉพาะทางเศรษฐศาสตร์บ้าง เช่น Professor Susan Athey นักเศรษฐศาสตร์ชั้นแนวหน้าที่ Stanford ได้ตีพิมพ์ใน Journal of Econometrics (Athey S, Imbens G, Metzger J, Munro E; 2021) เพื่อประยุกต์แบบจำลอง GANs สำหรับการจำลองแบบ Monte Carlo เพื่อสร้างข้อมูลที่ใกล้เคียงกับข้อมูลจริง โดยเป้าหมาย คือ เพื่อเปรียบเทียบแบบจำลองทางเศรษฐมิติและแบบจำลอง machine learning ประเภทต่างๆ สำหรับข้อมูลที่ใช้ศึกษาผลกระทบของนโยบาย (impact evaluation) ซึ่งเธอพบว่า แบบจำลอง GANs มีประโยชน์ในการสร้างข้อมูลทางเศรษฐศาสตร์ขึ้นมาใหม่อย่างเป็นระบบ ทำให้มีขนาดตัวอย่างที่ใหญ่ขึ้น สำหรับประเมินเปรียบเทียบแบบจำลองต่าง ๆ, หรือ มีหนังสือที่เขียนโดย Isaiah Hull (PhD in Economics, Boston College) คือ Machine Learning for Economics and Finance in TensorFlow 2 (2021) ซึ่งในบทที่ 9 มีอธิบายและตัวอย่างแบบจำลอง GANs
ปัจจุบันมีการประยุกต์ใช้แบบจำลองปัญญาประดิษฐ์ประเภท Deep Learning ทางเศรษฐศาสตร์ หรือ โปรแกรม Stata ที่นิยมใช้อย่างแพร่หลายทางเศรษฐศาสตร์และสังคมศาสตร์ ก็มีชุดคำสั่งของ Stata ด้าน Machine Learning ในอนาคตเราอาจจะมีโอกาสได้เห็นการประยุกต์ใช้แบบจำลอง GANs ในงานวิจัยทางเศรษฐศาสตร์ เพราะความสามารถในการสร้างข้อมูลใหม่ เช่น
อย่างไรก็ตาม แบบจำลอง GANs ก็มีข้อจำกัดที่สำคัญ คือ การขาดผู้มีความรู้ความเชี่ยวชาญเฉพาะทาง, การฝึกฝน (train) แบบจำลองเป็นเรื่องยากและท้าทาย, และ หากต้องการวิเคราะห์ระบบที่ซับซ้อน ควรจะต้องมีข้อมูลจำนวนมาก และใช้เวลานาน ยิ่งไปกว่านั้น ยังมีความท้าทายทางเทคนิค เช่น mode collapse คือ โครงข่าย Generator ไม่สามารถสร้างผลลัพธ์ที่มีความหลากหลาย ตลอดจนการไม่ลู่เข้า (non-convergence) หรือ ความไม่เสถียร (instability) ซึ่งอาจเกิดจากความไม่เหมาะสมของการออกแบบสถาปัตยกรรม, การกำหนดฟังก์ชันวัตถุประสงค์ (objective function), หรือ ปัญหาการเลือก optimization algorithm
แม้อาจจะมีข้อจำกัดหรือความท้าทาย แต่ศักยภาพของการประยุกต์ใช้แบบจำลอง GANs ในงานวิจัยทางเศรษฐศาสตร์นั้น ยังเป็นพรมแดนความรู้ใหม่ที่กำลังรอให้ค้นหาและพัฒนา ซึ่งอาจจะช่วยให้เราสามารถเข้าใจปรากฏการณ์ทางเศรษฐกิจได้ลึกซึ้งขึ้น ช่วยออกแบบนโยบายที่มีประสิทธิภาพมากขึ้น และ สามารถคาดการณ์แนวโน้มเศรษฐกิจในอนาคตได้ดีขึ้น ด้วยพลังของปัญญาประดิษฐ์ ความสามารถในการประมวลผลของคอมพิวเตอร์ และ วิทยาการความรู้ของมนุษยชาติ



